Training a 360M Parameter Model with Performance Discipline
Overview
I want to develop intuition for frontier-scale AI systems performance engineering. Rather than starting with a massive distributed setup, I am deliberately constraining myself to something small and easy to reason about: pretraining a language model on a single GPU, for a fixed wall-clock GPU budget while paying attention to where compute goes.
More concretely, the goal is to pretrain the SmolLM-360M parameter model1 on a story like dataset, using one NVIDIA A100 (80GB) for 30 hours. Instead of attempting to train a great model, we will attempt to train a model responsibly with discipline around feasibility, throughput, and hardware efficiency.
So we care about stuff like:
- How to reason about feasibility before writing code
- How to measure training efficiency in a way that matters
- Which optimizations are worth during tight compute constraints.
If you want to skip everything and directly jump into the code or reproduce it yourself, it's available at this repo.
Feasibility Math
What's even feasible with the constraints we have? I will use a standard back-of-the-envelope approximation for transformer training compute:
where
- is training compute in FLOPs
- is the number of model parameters
- is the number of training tokens.2
And here are the fixed constraints:
- Model size: 360M parameters
- GPU: single A100 (80GB)
- Precision: bfloat16
- Wall-clock time: 30 hours
The A100 has a peak BF16 throughput of roughly 312 TFLOPS.3 I do not expect to reach the peak of course. What MFU should I target? Looking at published numbers, Meta reported 38-43% MFU for Llama 3 training4 and Google achieved 46% for PaLM5 with extensive optimizations. For a single-GPU training job with a non-trivial input pipeline, a 40% MFU target seems both realistic. That gives an effective sustained throughput of roughly 125 TFLOPS.
That means over 30 hours we can perform,
Solving for dataset size,
So, under optimistic yet reasonable assumptions, this setup can process approximately 6B tokens in 30 hours. We will treat this number not as a promise but as a budget and everything that follows should respect it.
Scaling Laws as Budgeting Tools
I will now use scaling laws as a means of capacity planning to avoid wasting compute. From the Chinchilla scaling law2, we have:
My feasibility math says I can afford ~6B tokens. That puts this run at roughly 83% of the Chinchilla-optimal data regime.
An important distinction: Chinchilla-optimal training is not the same as training until convergence. Compute-optimal training is concerned with the question: “Given a fixed compute budget, how do I allocated it between model size and dataset size to get the best result?” The answer is to stop training when your budget runs out even if the loss is decreasing. The model remains “undertrained” relative to its full capacity.
Training until convergence is a different goal entirely. You keep training until the loss plateaus and additional tokens provide negligible improvement. This requires far more data (often 100x the parameter count or more) and multiple epochs over the dataset. Llama 3, for instance, trained its 70B model on 15T+ tokens4 prioritizing final model quality over training efficiency.
For this project, I am deliberately targeting near compute-optimal as the goal is to learn performance discipline under a fixed 30-hour budget. The loss might still be decreasing when my compute runs out.
Choosing Learning Rate and Batch Size
For a model of this size, the literature consistently points to
- Learning Rate:
- Global Batch Size: tokens
I will treat these as architectural constants for this project. They are not sacred but good enough (which is probably a virtue) when compute is scarce.
Small batch sizes early in training can move the model quickly through the loss landscape but later in the training small batch size means noisy gradients. They also require more optimizer steps for the same amount of tokens. On the other hand, large batch sizes can give accurate gradient estimates but we make fewer parameter updates per token and the improvement in loss doesn’t compensate for the reduced number of gradient updates slowing down the convergence per token.
Under a fixed compute budget, there is a sweet spot6 and I am intentionally choosing a well-trodden one.
What I Actually Care to Measure
For this project, I care about three things:
- Tokens per second - this is the training throughput.
- Loss vs. Tokens - this is the sample efficiency
- Model FLOPs Utilization (MFU) - this measures hardware efficiency
MFU is defined as Actual FLOPS / Theoretical Peak FLOPS.5 If the MFU is low, the GPU is idle or doing non-useful work, and nothing else in the system matters to me.
# A100 80GB BF16 peak throughput
A100_PEAK_FLOPS = 312 * 10 ** 12
def calculate_mfu(tokens_per_second, num_params):
actual_flops = 6 * num_params * tokens_per_second
return 100 * actual_flops / A100_PEAK_FLOPS
Tweaks and Optimizations
Data Pipeline - Avoiding GPU Starvation
The fastest GPU is useless if it’s waiting on the CPU. Data loader inefficiencies can dominate training time through slow storage reads, expensive CPU-side preprocessing or inefficient host-to-device transfers. The guiding principle here is simple: GPU should never wait for data. If MFU is lower than expected, the data pipeline is the first place I will look into.
torch.compile: Paying Attention to Graph Breaks
I will use torch.compile to reduce Python overhead and enable kernel fusion. The appeal of it is large speedups with minimal code changes. The compilation isn’t free of course. It works by tracing the Python code and extracting tensor-only graphs which means unsupported operations result in a graph break. This means we need to watch out for fragmented graphs, reduced fusion opportunities, and recompilations triggered by dynamic shapes.
For this reason, I will monitor graph breaks explicitly, discount warm-up iterations when measuring MFU, and enforce consistent shapes and padding where possible. A compiler that recompiles mid-training is a "performance bug".
To diagnose graph breaks before training, I use torch._dynamo.explain which traces the model and reports where compilation boundaries occur:
# Check for graph breaks before training
with torch.autocast(device_type='cuda', dtype=torch.bfloat16):
explanation = torch._dynamo.explain(model)(dummy_input)
print(f'Graph count: {explanation.graph_count}')
print(f'Graph breaks: {explanation.graph_break_count}')
for reason in explanation.break_reasons:
print(f' - {reason}')
Running this on my model with the Flash Attention Triton kernels produces:
Graph count: 192
Graph breaks: 191
Break reasons:
- call torch._dynamo.disable() wrapped function <function apply_rotary_emb ...>
- call torch._dynamo.disable() wrapped function <function flash_attention ...>
- inline in skipfiles: TritonRMSNorm.forward ...
(repeated 4x per decoder layer × 32 layers)
These breaks are intentional: the @torch._dynamo.disable decorators mark the Triton kernels as compilation boundaries. Without them, the inductor backend would fail with 'Heuristics' object has no attribute '__name__' because it cannot trace through @triton.heuristics decorators. The solution is to selectively disable compilation for flash-attn operations:
@torch._dynamo.disable
def flash_attention(q, k, v, causal=True):
q = q.permute(0, 2, 1, 3)
k = k.permute(0, 2, 1, 3)
v = v.permute(0, 2, 1, 3)
return flash_attn_func(q, k, v, causal=causal)
@torch._dynamo.disable
def apply_rotary_emb(q, cos, sin, interleaved=False):
return _apply_rotary_emb(q, cos, sin, interleaved=interleaved)
This approach preserves torch.compile optimizations for everything else such as embeddings, linear projections, the MLP blocks, and loss computation, while treating the already hand-optimized Triton kernels as opaque function calls. The tradeoff: we get 192 smaller compiled graphs instead of one monolithic graph, but the boundaries fall exactly around the already hand-optimized kernels.
Mixed Precision: Using the Hardware as Intended
Training entirely in FP32 would leave most of the A100’s performance unused. I will use bfloat16 (BF16) automatic mixed precision (AMP) where we perform matrix multiplications in BF16 to exploit Tensor Cores and accumulation and weight updates in FP32 for numerical stability. BF16’s wider exponent range avoids the need for loss or gradient scaling, simplifying training while preserving stability.
Gradient Accumulation: Fitting the Batch into Memory
A global batch size of 250K tokens obviously doesn’t fit into 80GB of VRAM in a single pass. Gradient accumulation provides a mathematically equivalent alternative that trades time for memory. So what we do is:
- Split the batch into M micro-batches
- Perform M forward + backward passes on each micro-batch
- Sum gradients across M passes
- Apply the optimizer once
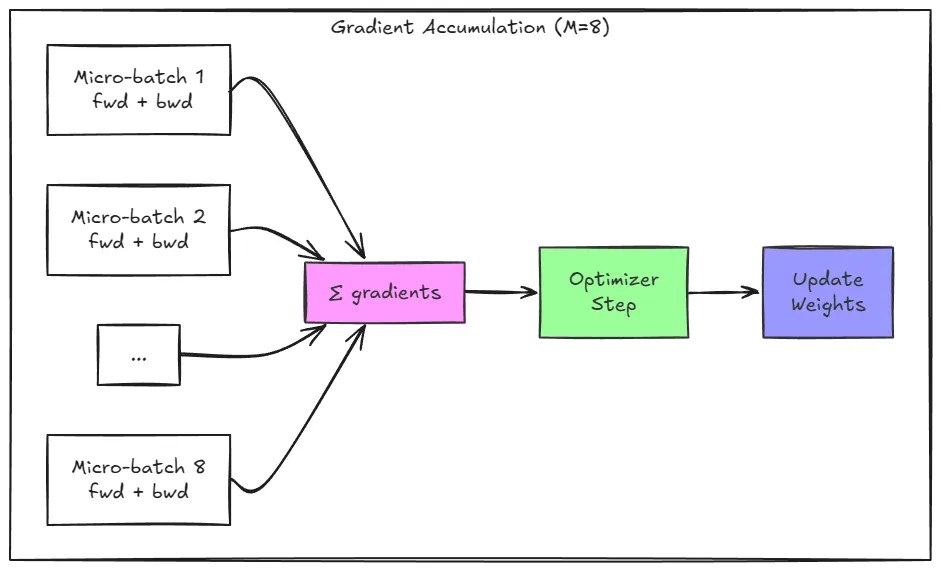
One small detail that matters enough is that the loss must be divided by the number of accumulation steps M. Failing to do so effectively scales the learning rate by M and usually leads to divergence. Gradient accumulation preserves the effective batch size and convergence behaviour while working within the memory limits. Although it increases latency of optimizer steps it preserves the throughput compared to a setting where we have the same micro-batch size as the batch size without gradient accumulation.
def train_step(model, data_loader, device, dtype, grad_acc_steps):
loss_acc = 0.0
for i in range(grad_acc_steps):
batch = next(data_loader)
input_ids = batch['input_ids'].to(device)
target_ids = batch['target_ids'].to(device)
with torch.autocast(device_type='cuda', dtype=dtype):
outputs = model(input_ids=input_ids)
loss = F.cross_entropy(...) / grad_acc_steps # Scale loss!
loss.backward()
loss_acc += loss.item()
return loss_acc
What I excluded intentionally
This post concerns itself with whether 1) GPU stays busy, 2) MFU matches first-principles expectations, 3) loss decreases smoothly with tokens and 4) nothing obvious is being wasted. I didn’t prioritize the model’s capabilities or evaluate qualitative samples it generates. If the system fails, I want it to fail loudly and lend itself to diagnosis.
Results and Diagnostics
Preflight Run - 1
Before committing to a full 30-hour training run, I ran a preflight experiment on 10 million tokens to validate that the system works end-to-end and to establish baseline performance metrics. The dataset I chose is the 10B token sample of FineWeb-Edu7, a curated high-quality educational corpus meant for language model training.
Tokenization: CPU Bound Bottleneck
The first challenge I encountered was tokenization throughput. I noticed low CPU utilization when running dataset tokenization so I did some experimenting. Running nproc on my machine returned 252 available cores but naively using all of them actually hurt performance. I observed memory usage spiking to 99% suggesting that too many parallel processes were competing for memory bandwidth causing swapping and thrashing.
There’s no universal formula for how many workers would be optimal as it depends on dataset size, tokenizer complexity/overhead and available RAM. I ended up settling on 48 parallel processes. My reasoning was simple: with roughly 100GB of RAM available and assuming each worker requires approximately 2GB, 50 workers represented a reasonable upper bound. With this configuration, I observed near 100% CPU utilization and the full 10B token dataset completed tokenization in under 18 minutes.
I also noticed that token IDs were being stored as int64 by default, which didn’t make sense given that the SmolLM vocabulary contains fewer than 50,000 tokens8. Switching to int32 halved the memory footprint of the tokenized dataset with no loss of information.
Data Loading: Hiding I/O Latency
For the data loader I used 4 parallel workers to prefetch batches to GPU. Since batch loading is I/O bound, we don't need many workers, just enough to ensure the next batch is ready by the time GPU finishes processing the current one. The goal is to hide the I/O latency so the GPU never starves for the data.
DataLoader(
tokenized_dataset,
batch_size=micro_batch_size,
pin_memory=True, # Stage batches in pinned CPU memory for faster GPU transfer
num_workers=4, # Parallel workers prefetch next batches during GPU compute
)
torch.compile and Flash Attention
As discussed in the methodology section, torch.compile required selectively disabling compilation for Flash Attention's Triton kernels using @torch._dynamo.disable. This resulted in 192 smaller compiled graphs with intentional boundaries around the already hand-optimized kernels.
Results
The preflight run completed with the following metrics:
| Metric | Value | Assessment |
|---|---|---|
| Loss | 10.9 → 6.2 | Healthy decrease over 10M tokens |
| MFU | 40.6% | Seems good but probably could be better |
| Throughput (tokens per second) | 51,658 tokens / sec | Stable after the initial warmup steps |
| Memory Usage | 37GB / 80GB | Only 46% utilization |
The MFU of 40% seems respectable as it falls within the range Meta reported for Llama 3 training. However, the memory utilization of only 46% suggests there is room to increase the micro-batch size, which could improve both MFU and throughput by giving the GPU more work per kernel launch.
Preflight Run - 2
Configuration Change
I doubled the micro-batch size from 32 to 64 while halving the gradient accumulation steps from 16 to 8. This keeps the global batch size unchanged at ~262K tokens per optimizer step, but processes more tokens per forward pass. The hypothesis is that larger micro-batches give the GPU more work per kernel launch reducing the relative overhead of memory transfers and kernel dispatch. I also disabled batch size warmup for this run since the goal is to stress test the memory usage at the full batch size.
Results
The configuration change yielded meaningful improvements:
| Metric | Preflight 1 | Preflight 2 |
|---|---|---|
| MFU | 40.6% | 44.6% |
| Throughput | 51,658 tokens/sec | 56,664 tokens/sec |
| Memory Usage | 37GB / 80 GB | 65GB / 80GB |
| Loss | 10.9 → 6.2 | 10.9 → 6.5 |
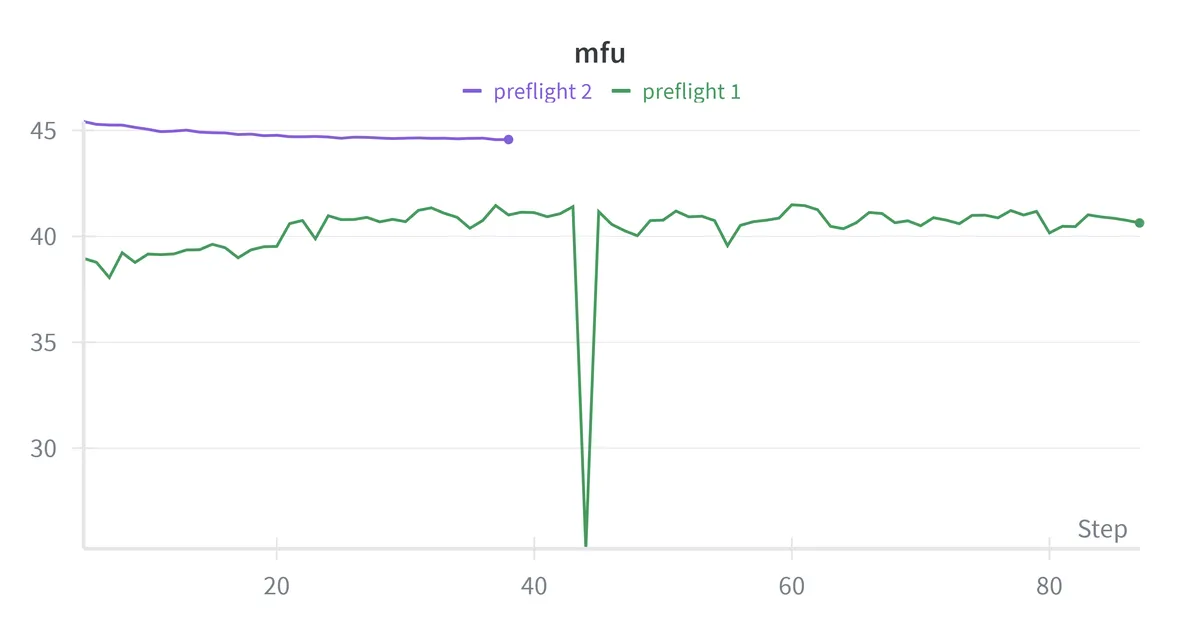
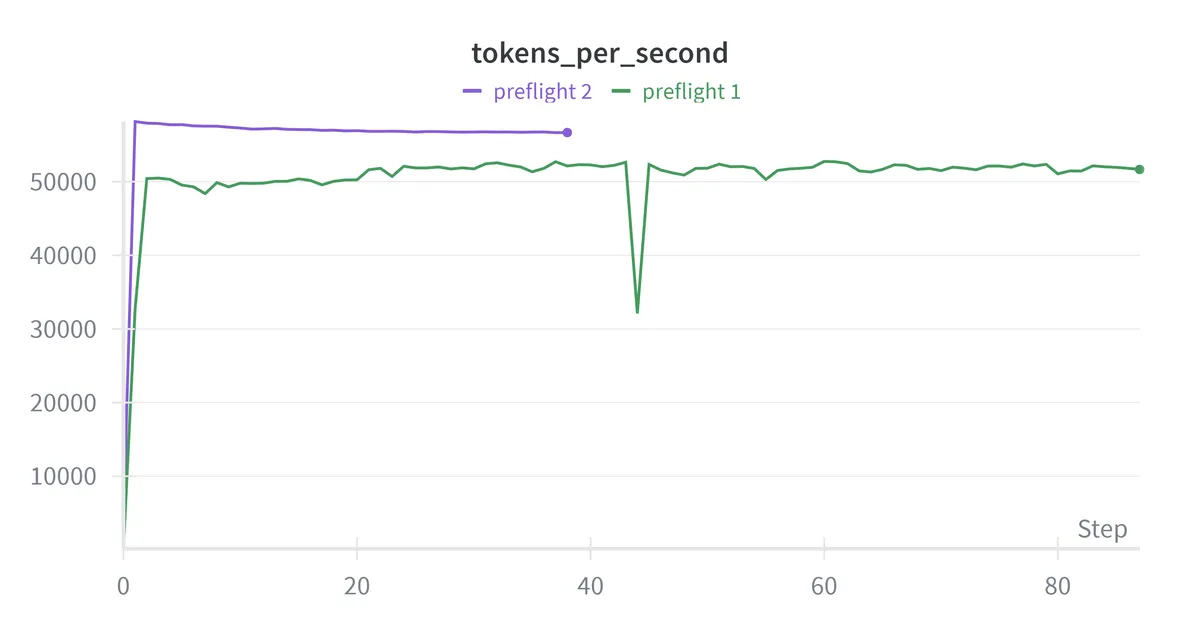
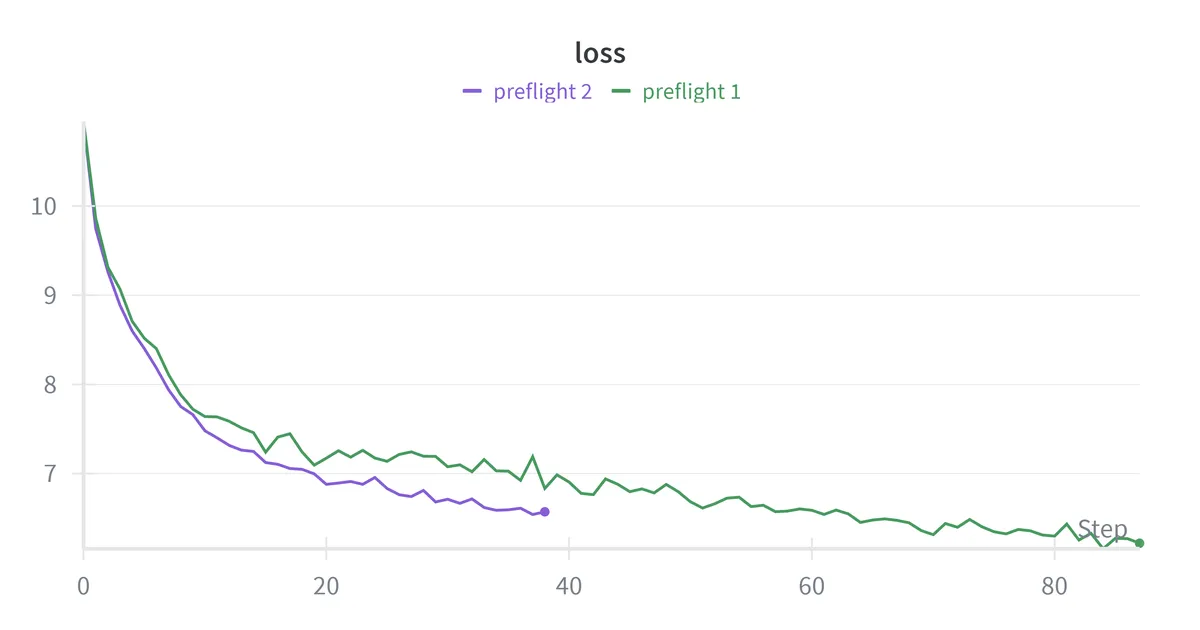
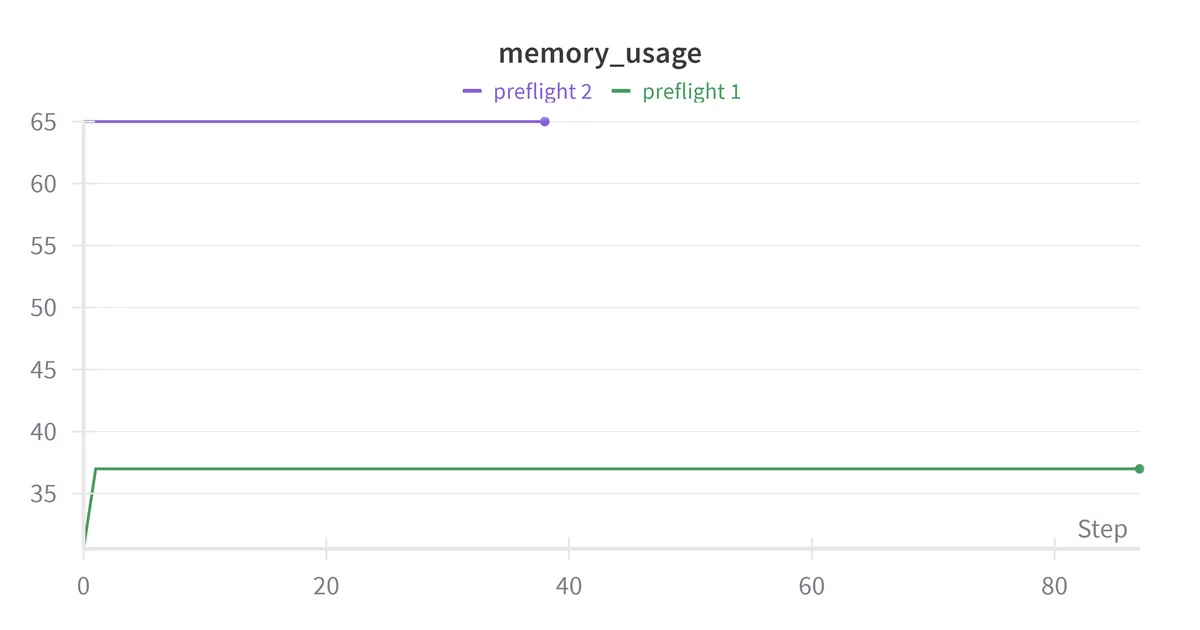
The MFU improvement indicates the GPU stays busier with increased micro-batch size. We are also now processing about 5,000 more tokens per second. Memory utilization of 81% is likely close to optimal and going higher might risk OOMs during occasional spikes while staying lower seems to be leaving performance on the table. Both the preflight runs validated that the system works: memory usage is flat, throughput is consistent, and loss decreases smoothly.
We are ready for the 30-hour hero run.
Hero Run
I launched the full training run targeting 6B tokens on FineWeb-Edu using the optimized configuration from the preflight runs:
| Parameter | Value |
|---|---|
| Micro-batch size (mbs) | 64 |
| Gradient accumulation steps (g) | 8 |
| Global batch size (mbs x g x seq length) | ~262K |
| Learning rate | 3e-4 |
| Batch size warmup | 500M tokens |
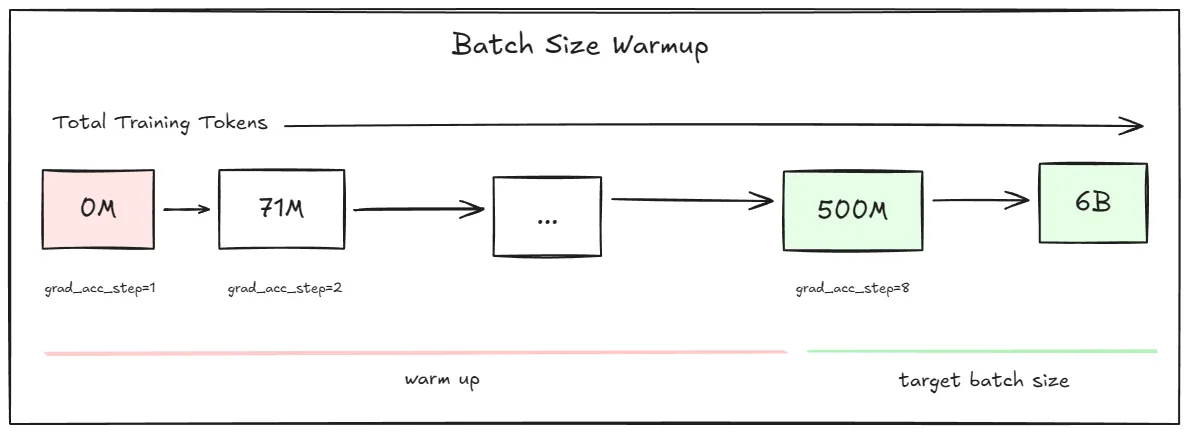
The batch size warmup follows the approach used in DeepSeek-V3 training9 where the effective batch size slowly increases during early training when gradients are large and noisy, then transitions to full batch size for efficient steady-state training. In my case, gradient accumulation steps ramped from 1 to 8 over the first 500M tokens.
Results:
| Metric | Value |
|---|---|
| Wall-clock time | ~29.5 hrs |
| Final loss | 2.96 |
| Final perplexity | ~19.3 |
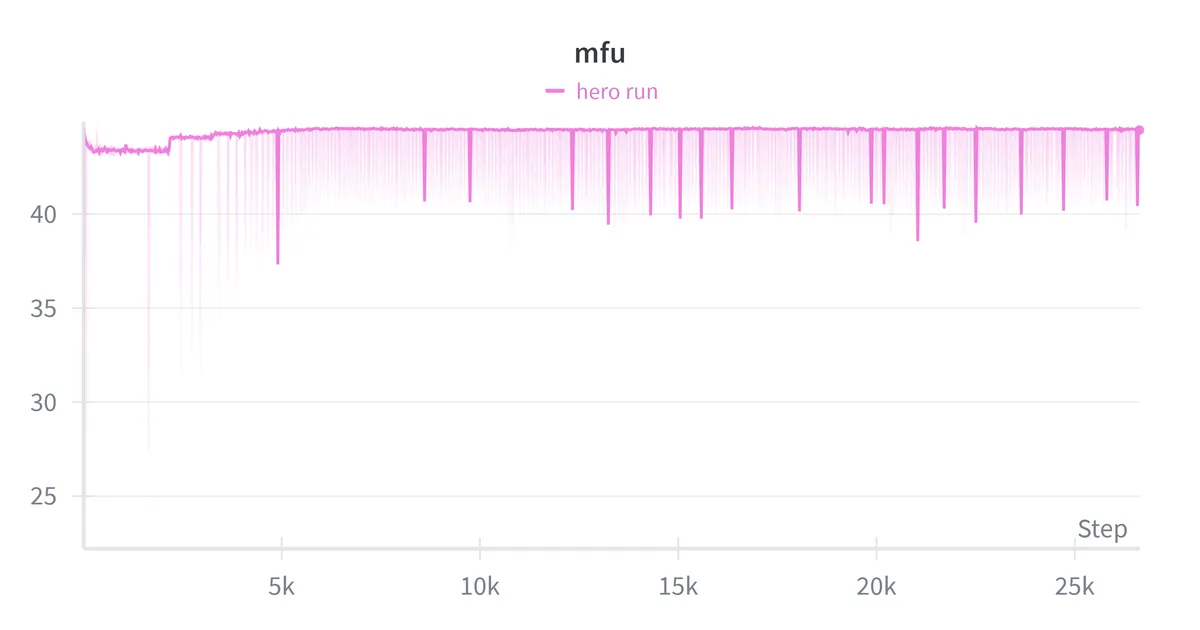
| Average MFU | 44.5% |
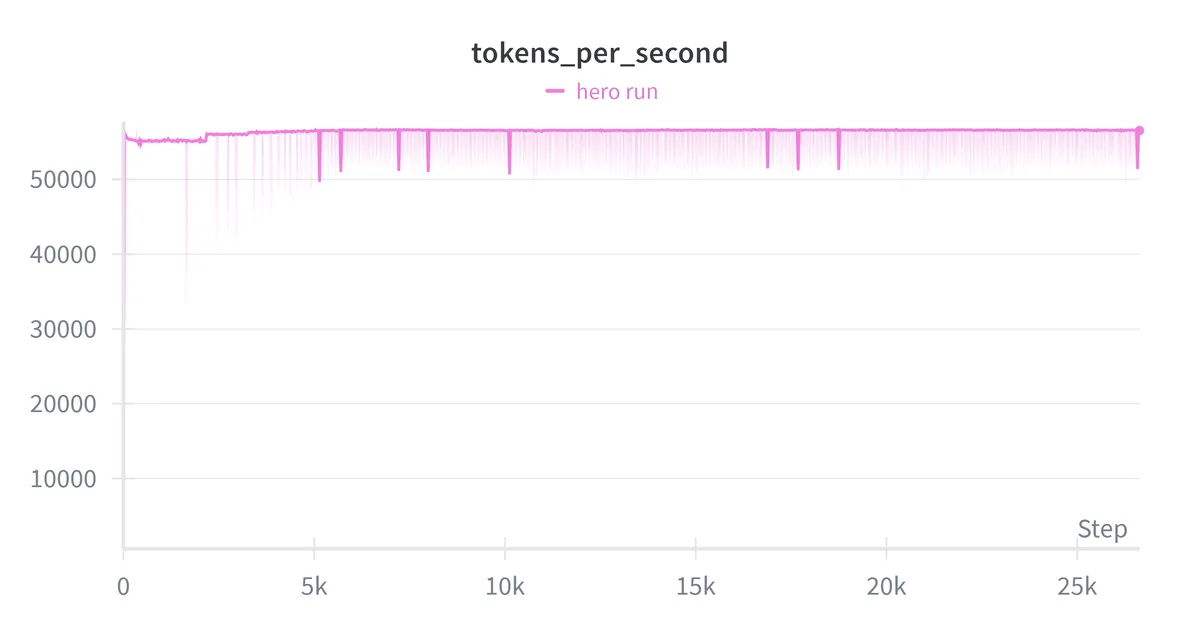
| Average throughput | 56,533 tokens/sec |
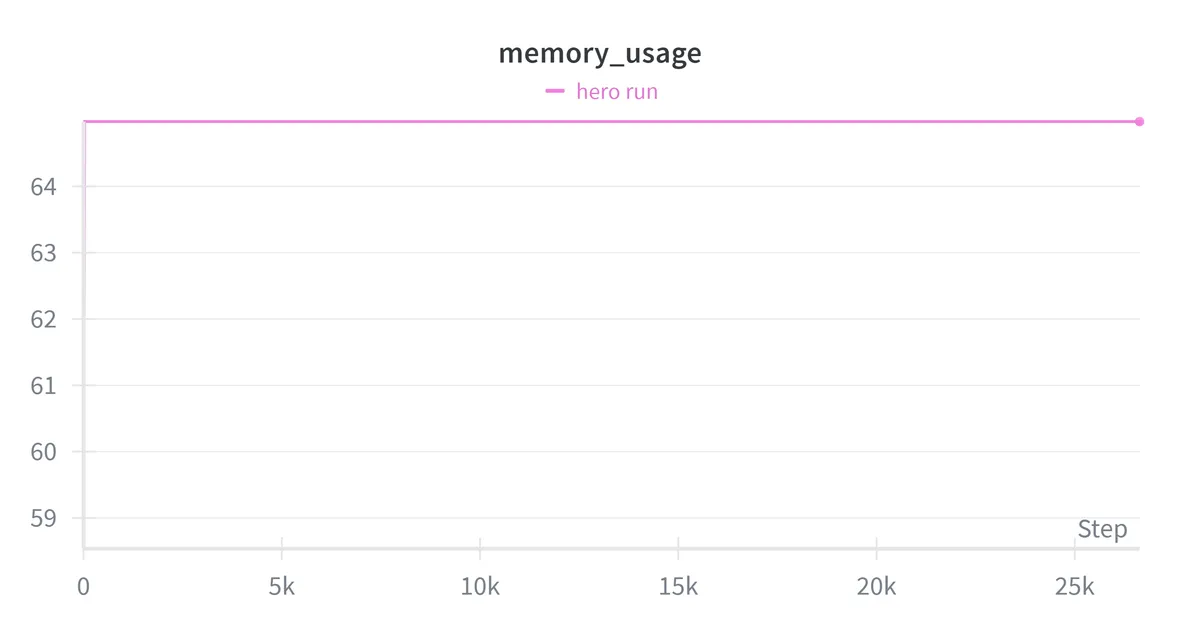
| Peak memory usage | ~65GB / 80GB |
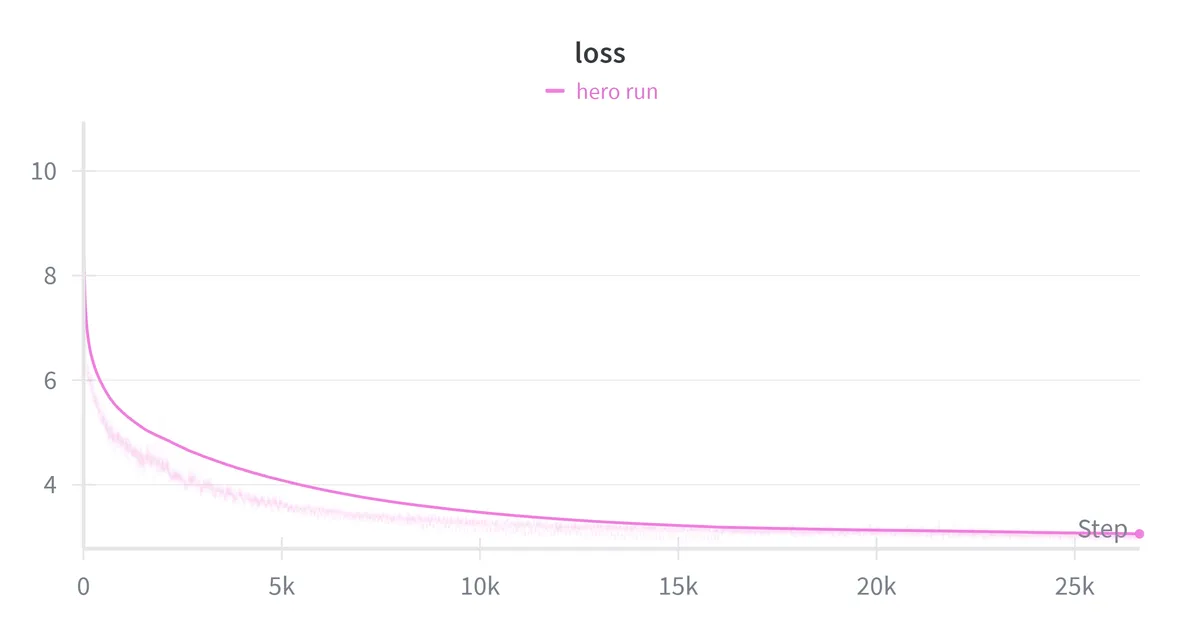
The final loss of 2.96 corresponds to a perplexity of 19.3. For reference, GPT-2 (124M parameters) achieved perplexity ~30 on WebText, while GPT-2 (1.5B parameters) achieved ~18.10 A 360M model landing at perplexity 19.3 sits between these reference points, slightly closer to the much larger model. Not a bad spot for our 360M parameter model.
My feasibility math predicted training on 6B tokens in 30 hours at 40% MFU. The actual run trained on 6B tokens in ~29.5 hours at ~44% MFU which is close to the estimate. The back of the envelope worked. As expected for near compute-optimal training, the loss was still decreasing when the token budget ran out.
Conclusion
This project set out to answer a simple question: can I reason about training feasibility, execute with discipline, and measure what matters, all on a single GPU?
What worked
- Feasibility math held up and seemed useful for avoiding wasted compute.
- Preflight runs were helpful revealing my initial configuration was underutilizing GPU memory. Doubling the micro-batch size improved both MFU and throughput.
- MFU matched production benchmarks and I think it's respectable achieving 44.5% MFU with a 360M parameter model on a single A100.
- Memory usage, throughput, and loss curves all behaved consistently from 10M tokens to 6B tokens. Nothing broke at scale that didn't break in preflight.
What I would do differently
Experiment with longer sequence lengths. I fixed sequence length at 512 tokens for simplicity, but modern models train on 2K–8K contexts. Longer sequences would change the memory-compute tradeoff and potentially improve MFU through better arithmetic intensity.
Implement learning rate scheduling. I used a constant learning rate for simplicity. A warmup + cosine decay schedule might improve final loss, though for a compute-optimal run, the difference may be small.
If you're interested in exploring the code or reproducing it yourself, it's available at this repo.
HuggingFace SmolLM-360M. https://huggingface.co/HuggingFaceTB/SmolLM-360M↩
Hoffmann et al., "Training Compute-Optimal Large Language Models", 2022. https://arxiv.org/abs/2203.15556↩
NVIDIA A100 Tensor Core GPU Datasheet. https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/a100/pdf/nvidia-a100-datasheet.pdf↩
Meta AI, "The Llama 3 Herd of Models", 2024. https://arxiv.org/abs/2407.21783↩
Chowdhery et al., "PaLM: Scaling Language Modeling with Pathways", 2022. https://arxiv.org/abs/2204.02311↩
HuggingFace Ultra-Scale Playbook. https://huggingface.co/spaces/nanotron/ultrascale-playbook↩
HuggingFace FineWeb-Edu 10B Token Sample. https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu/viewer/sample-10BT↩
SmolLM-360M Config. https://huggingface.co/HuggingFaceTB/SmolLM-360M/blob/main/config.json↩
DeepSeek-AI, "DeepSeek-V3 Technical Report", 2024. https://arxiv.org/abs/2412.19437↩
Radford et al., "Language Models are Unsupervised Multitask Learners", 2019. https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf↩